Show it once. It generalizes everywhere.
TP-GPT learns a robot policy from a single demonstration. Drag objects, draw paths, or pose the arm — watch it adapt in real time.
Generalization in action
One demonstration. Three tasks. Zero retraining.
Reshelving
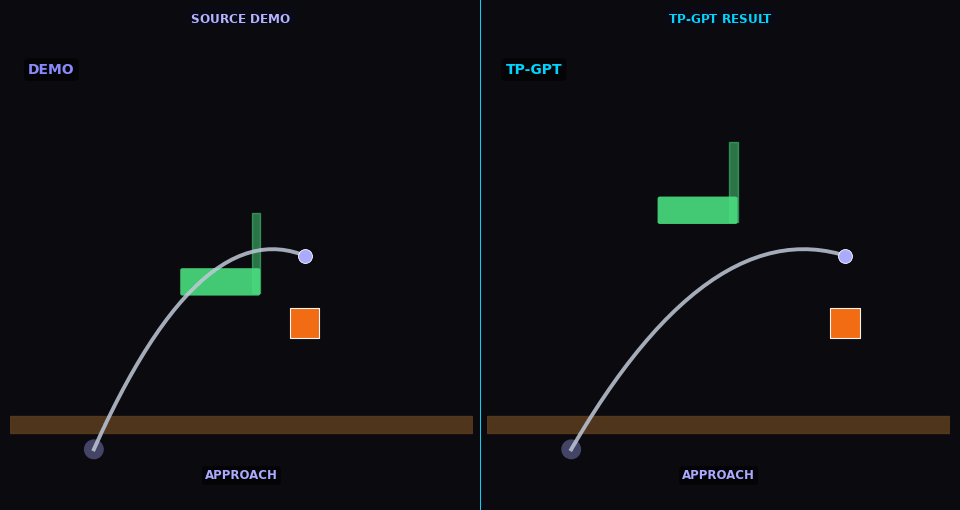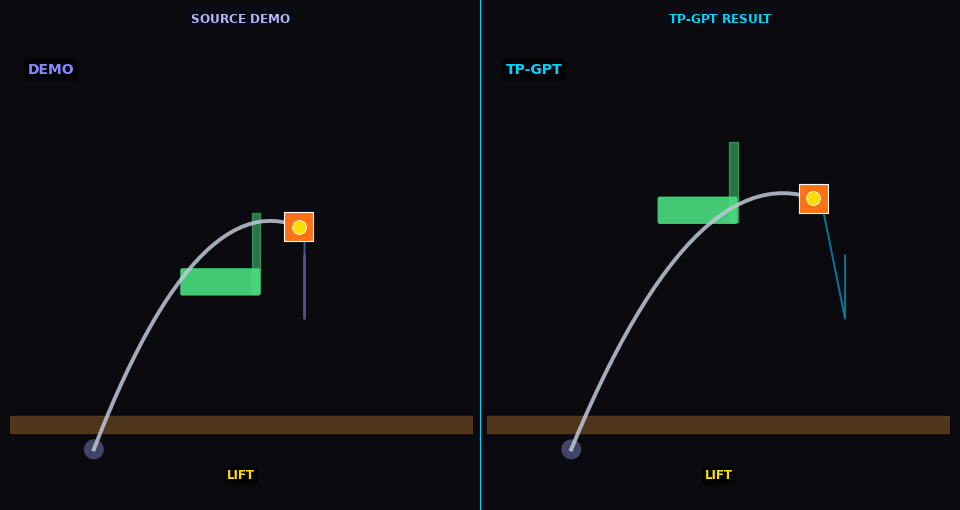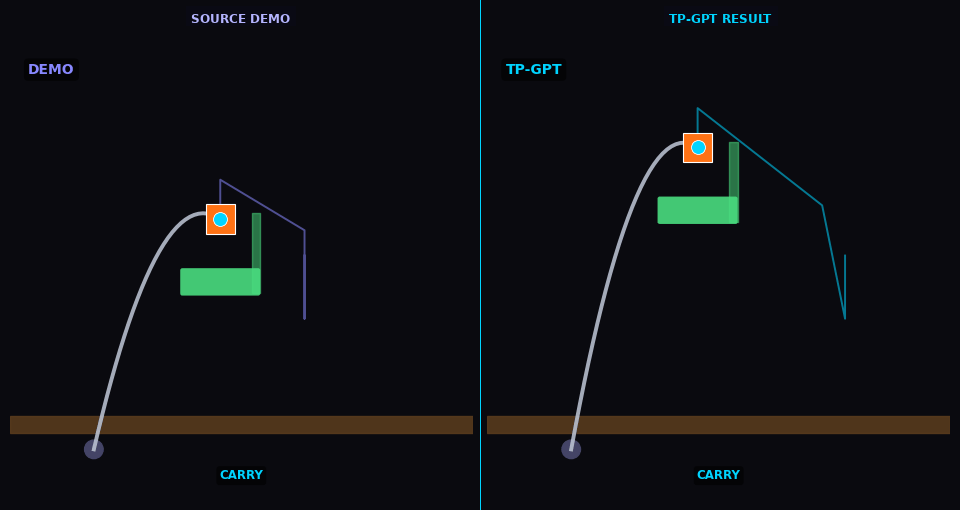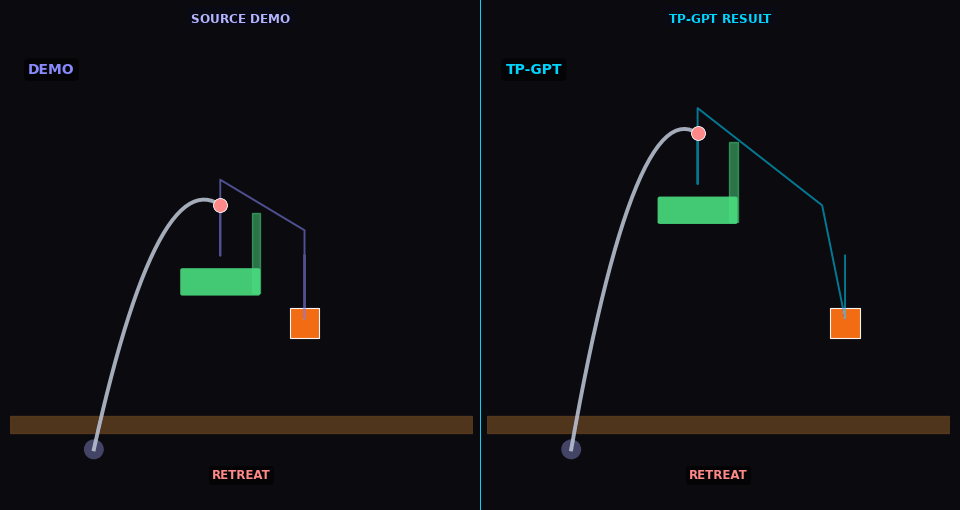
TP-GPT transports pick-place policy to new object/goal positions
Cleaning
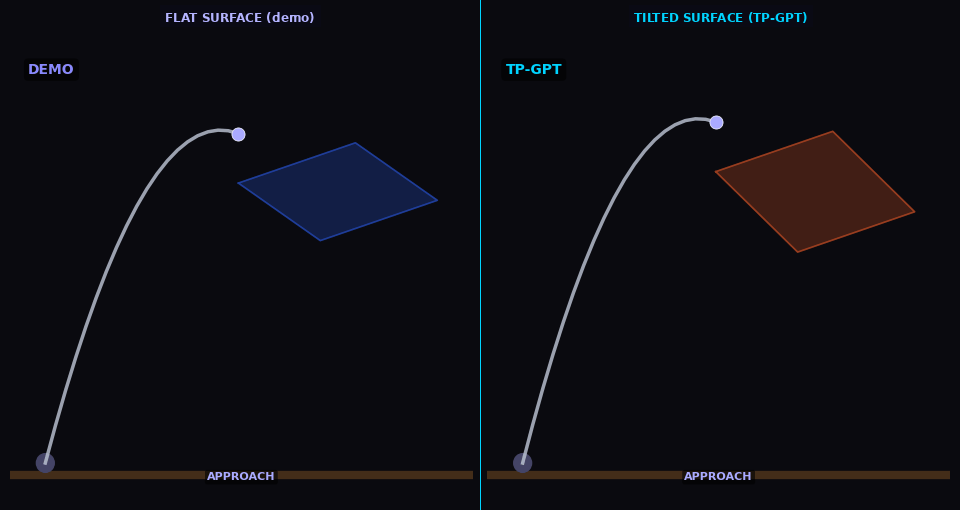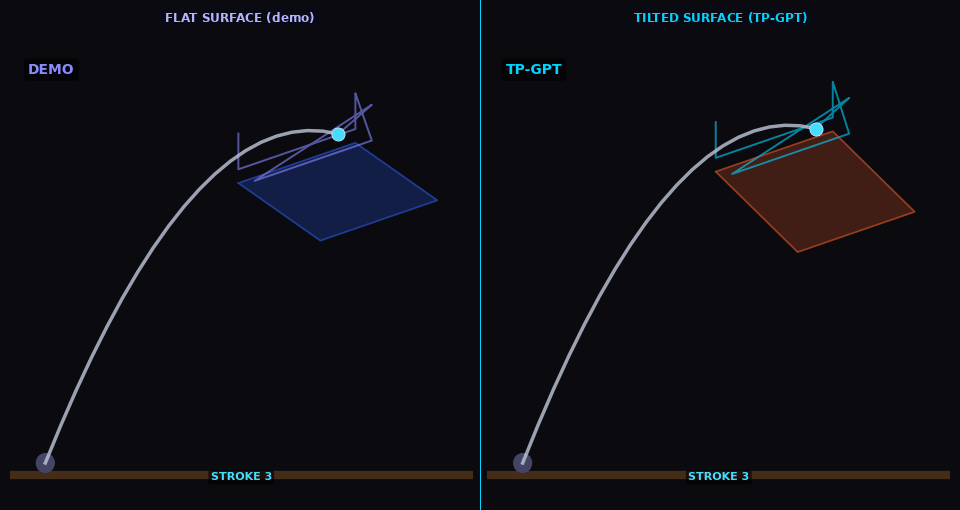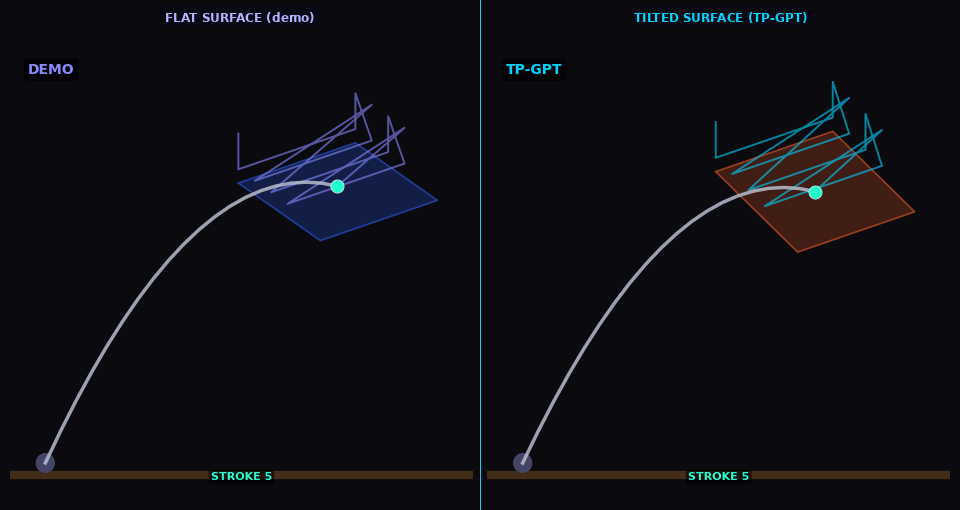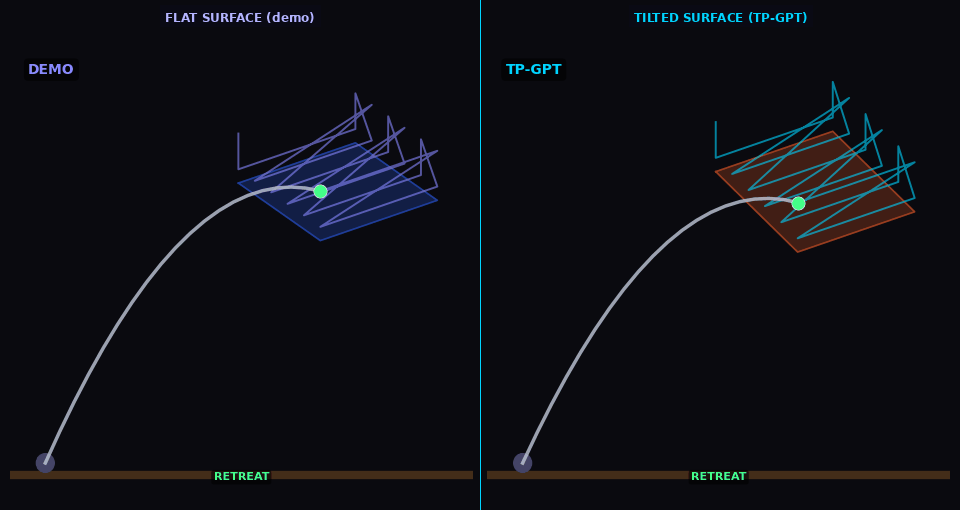
TP-GPT adapts cleaning path to shifted surface
Arm-pose
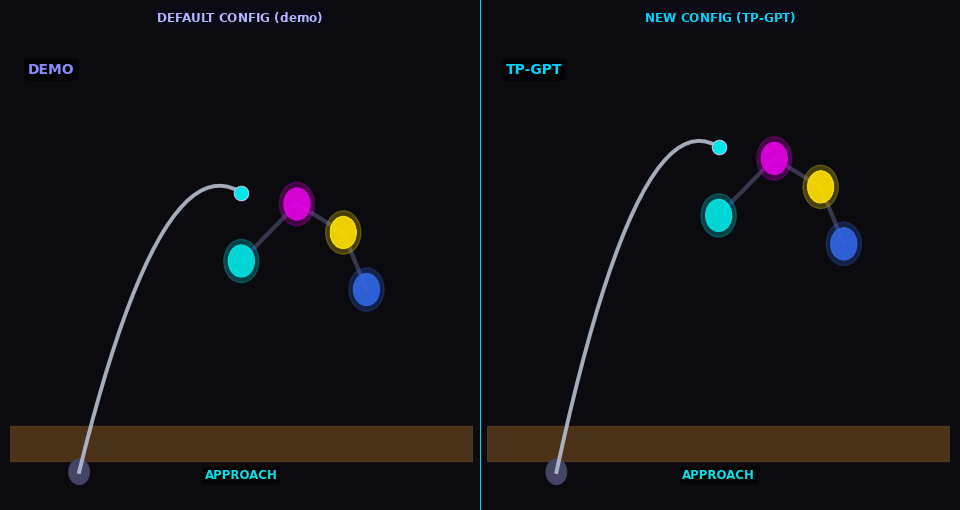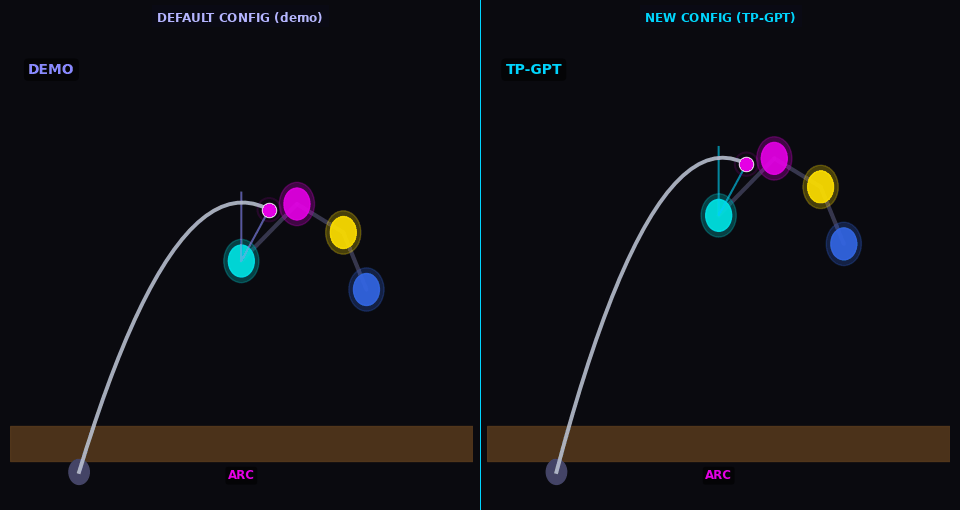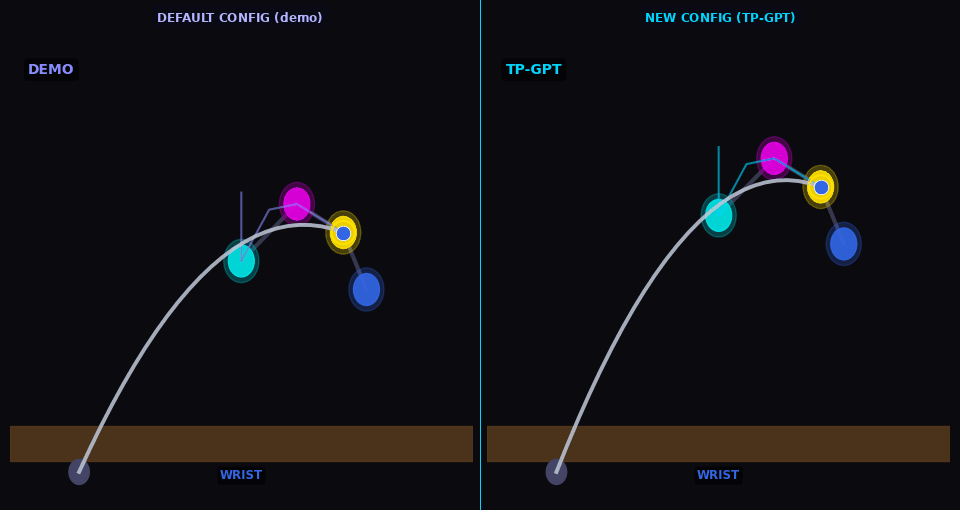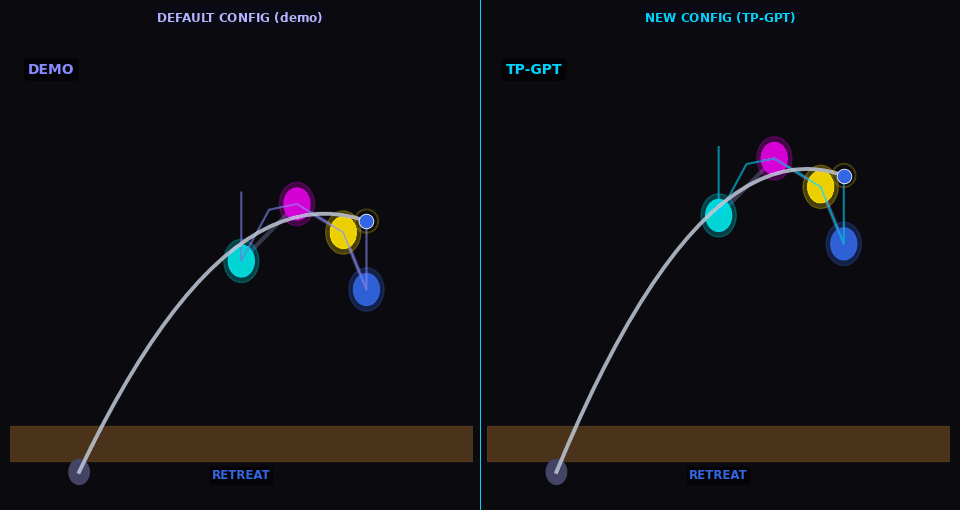
TP-GPT traces path through new arm configuration (analog of Sec. V-B dressing — cloth sim. not available in kinematic MuJoCo)
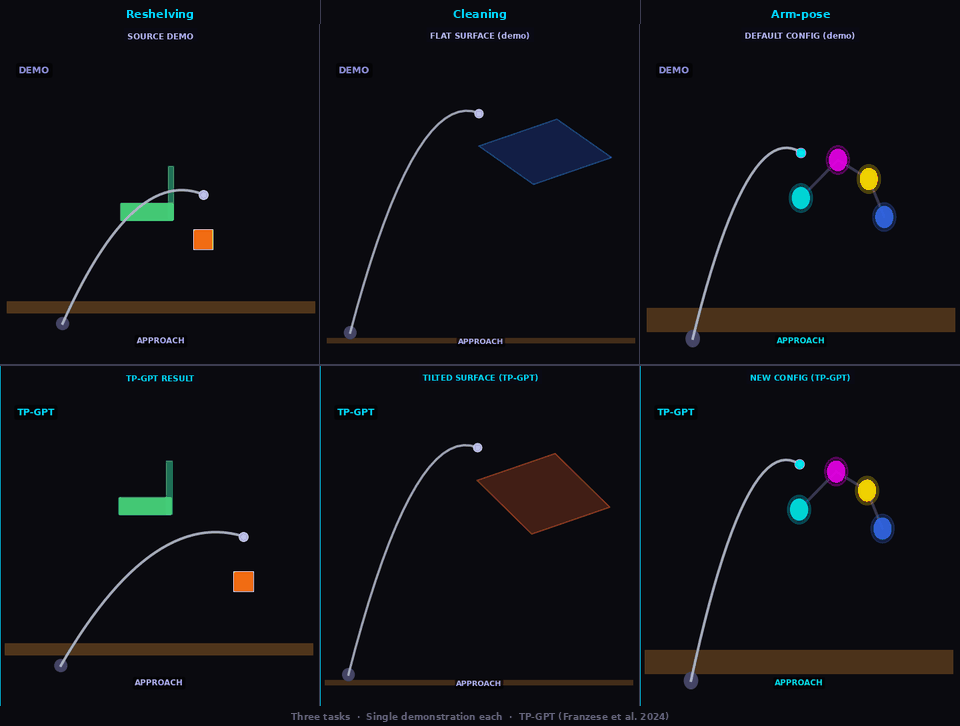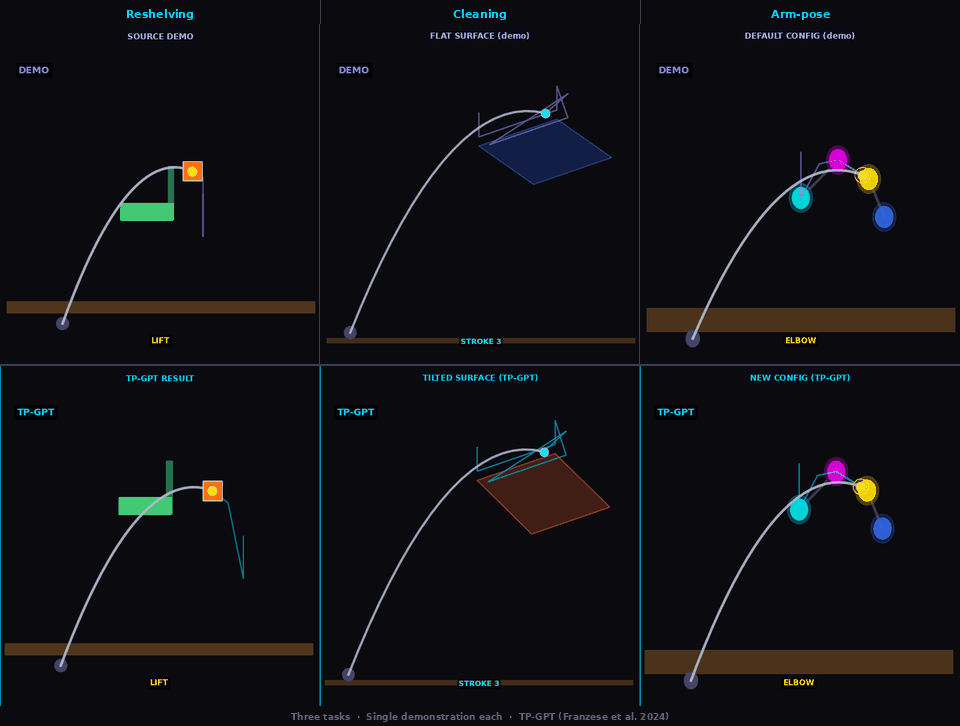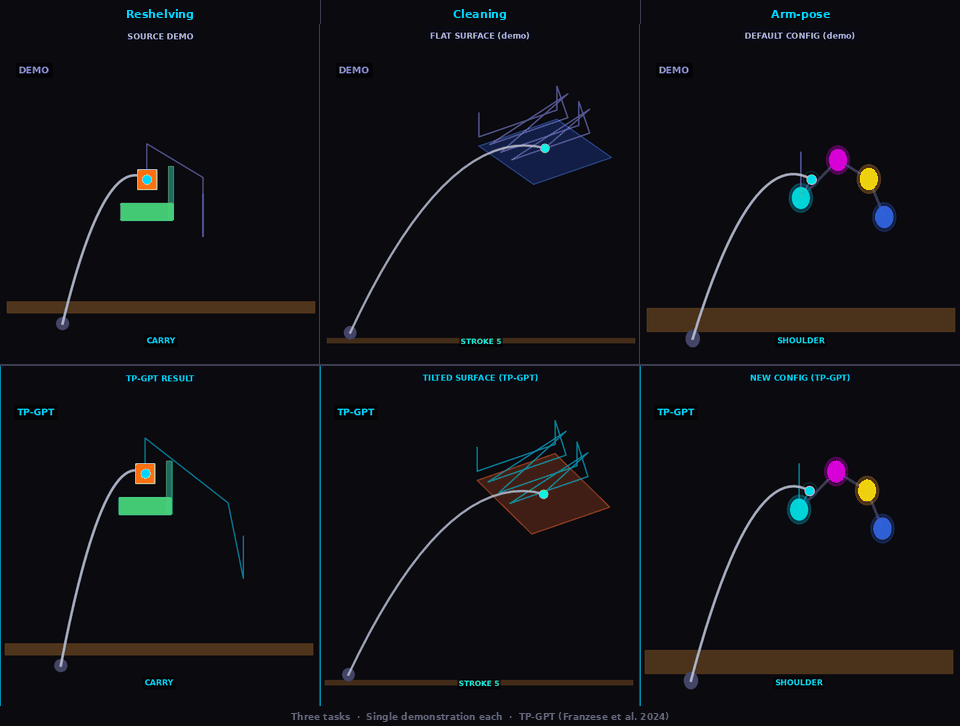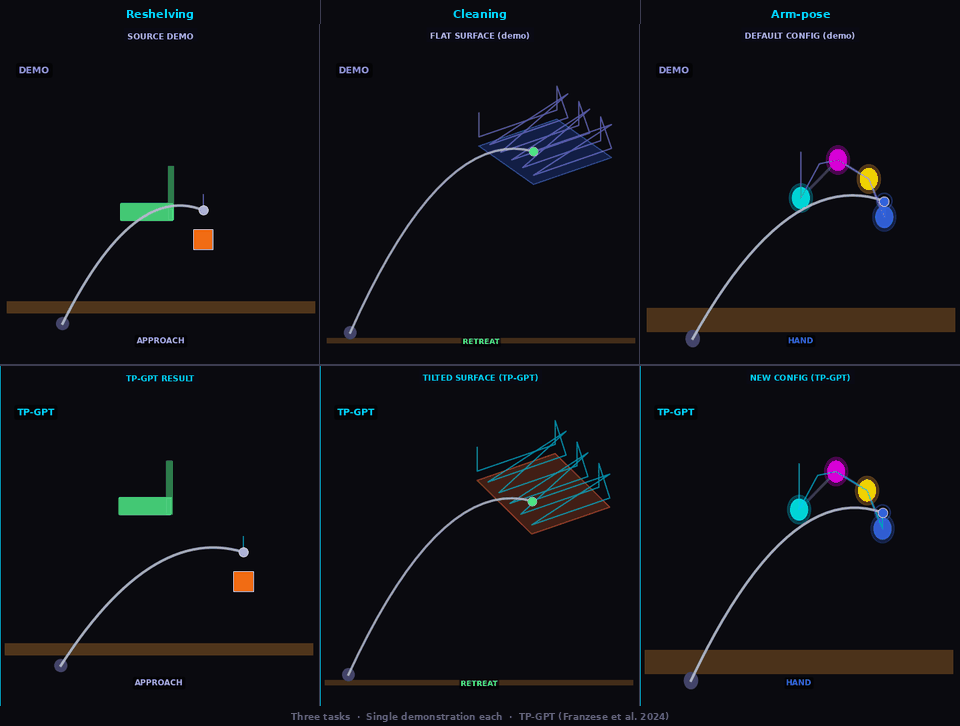
Three tasks · Single demonstration each · Franka Panda arm · MuJoCo kinematic simulation
Interactive demo
Try it yourself
Configure the scene
Drag objects to new positions,
then click Generalize.
Loading controls…
Runs TP-GPT inference in your browser and animates the transported policy on the arm.
The TP-GPT Algorithm
Four steps from a single demonstration to a generalized policy. Based on Franzese et al. 2024.
Learn from demonstration
A Gaussian Process fits the velocity field ẋ = f(x) from a single kinesthetic demonstration. The GP's zero-mean prior ensures zero velocity in regions with no evidence — the robot stays still unless it has seen training data nearby.
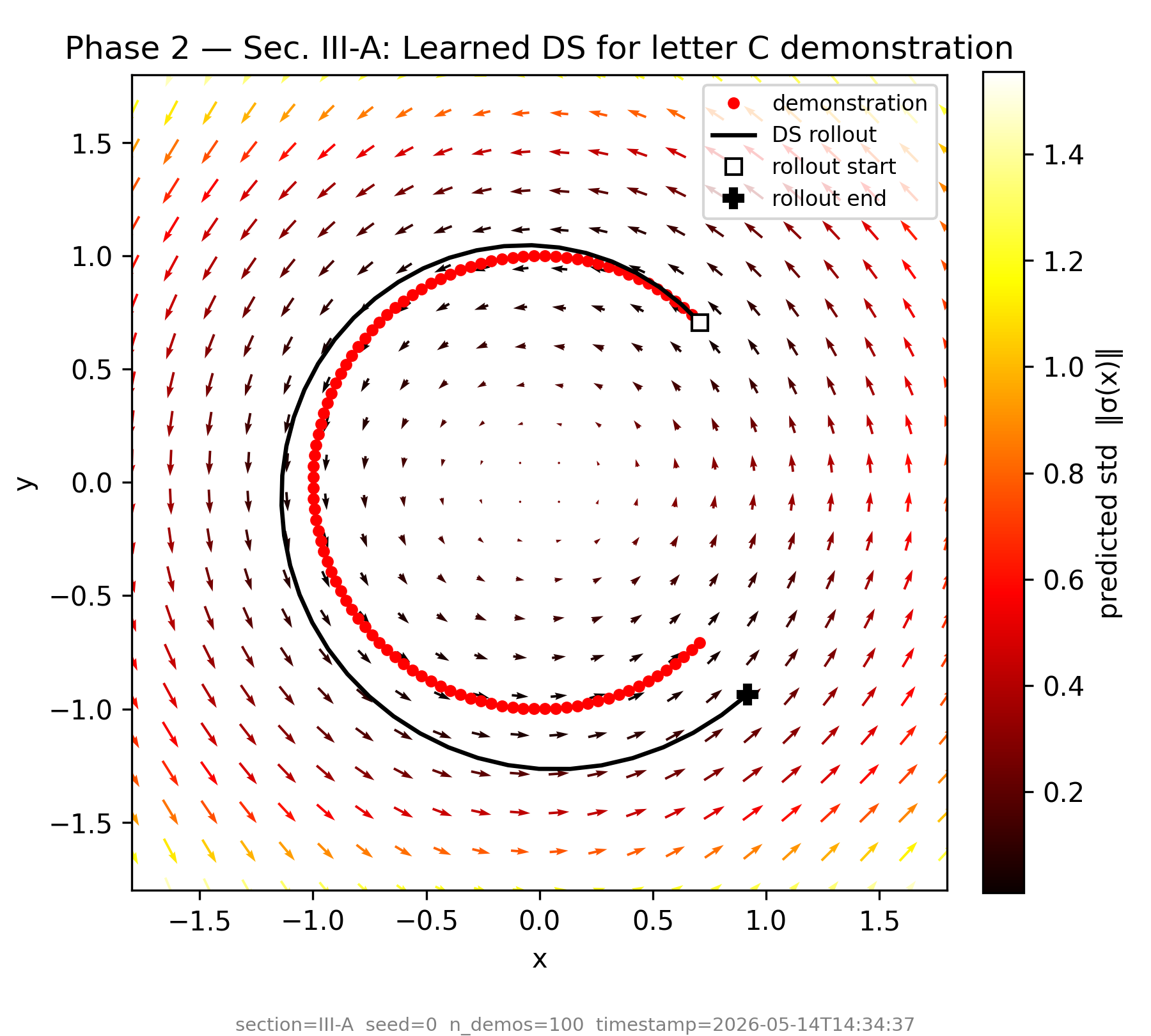 Learned velocity field · letter-C demo · Sec. III-A
Learned velocity field · letter-C demo · Sec. III-A
Track keypoints
Source keypoints S (e.g. box corners, shelf slot corners) and target keypoints T define how the scene has changed. Just a handful of paired points — no full scene reconstruction needed.
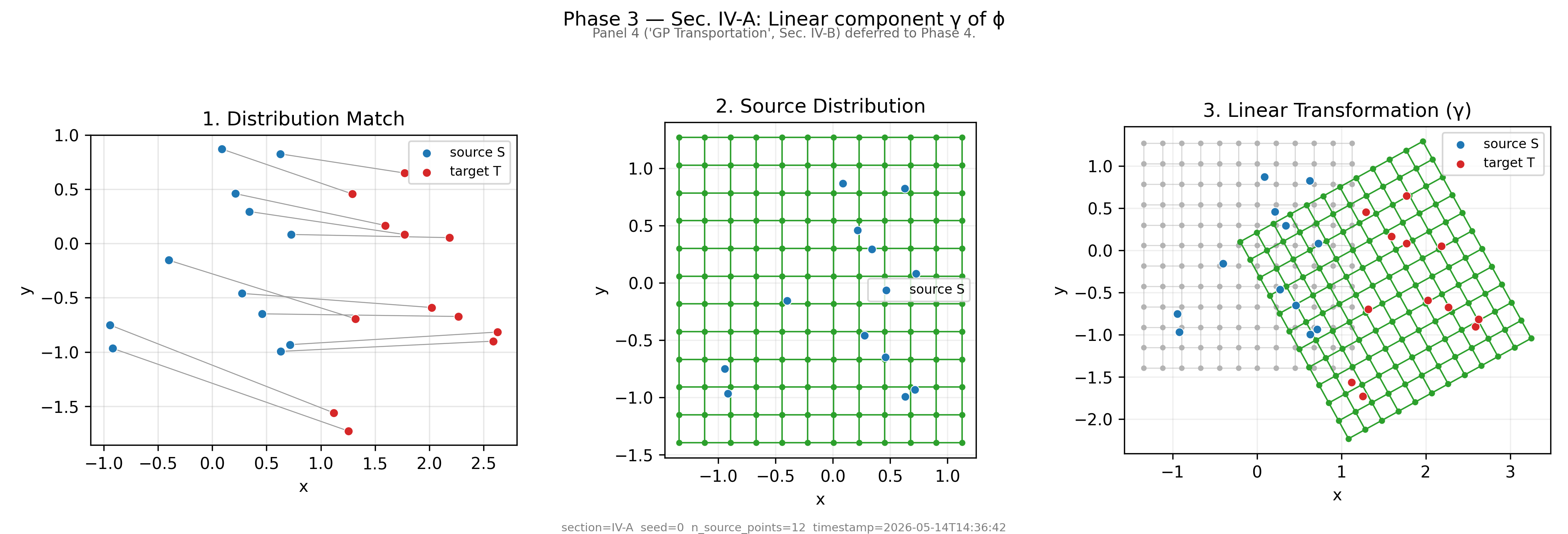 Source → target distributions · Fig. 3 (panels 1–3) · Sec. III-E
Source → target distributions · Fig. 3 (panels 1–3) · Sec. III-E
Transport the policy
The map ϕ(x) = γ(x) + ψ(γ(x)) transforms every point from source to target scene. γ is a linear SVD-based alignment; ψ is a GP correcting the nonlinear residual. Velocities, orientations, and stiffness are transported via the Jacobian J = ∂ϕ/∂x.
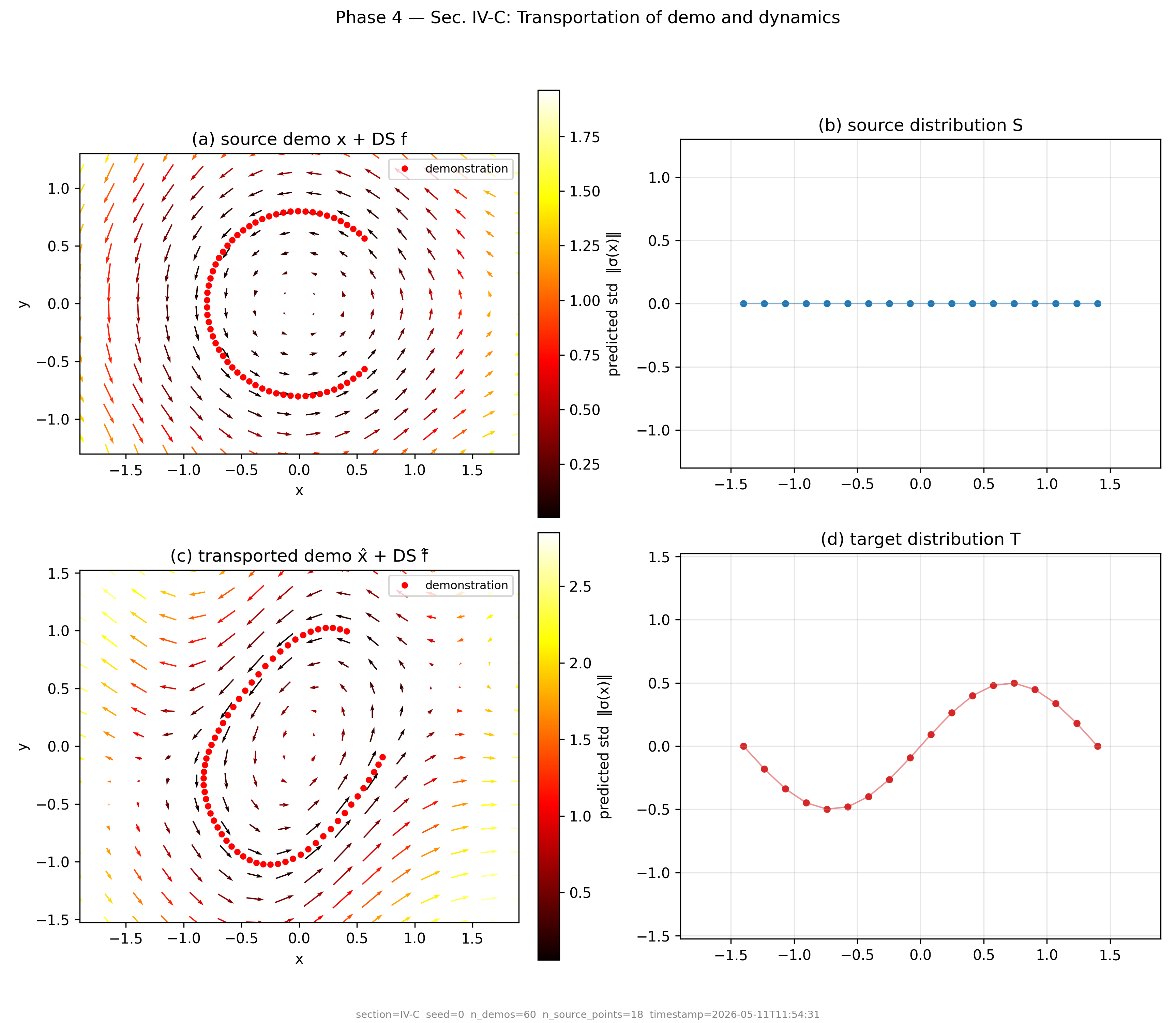 Transportation scheme · Fig. 5 · Sec. III-D
Transportation scheme · Fig. 5 · Sec. III-D
Execute with uncertainty
Total uncertainty Σ = Σ_transport + Σ_epistemic quantifies confidence everywhere in the workspace. High uncertainty near unexplored regions; low near training data. This guides the robot to slow down or seek corrections in uncertain areas.
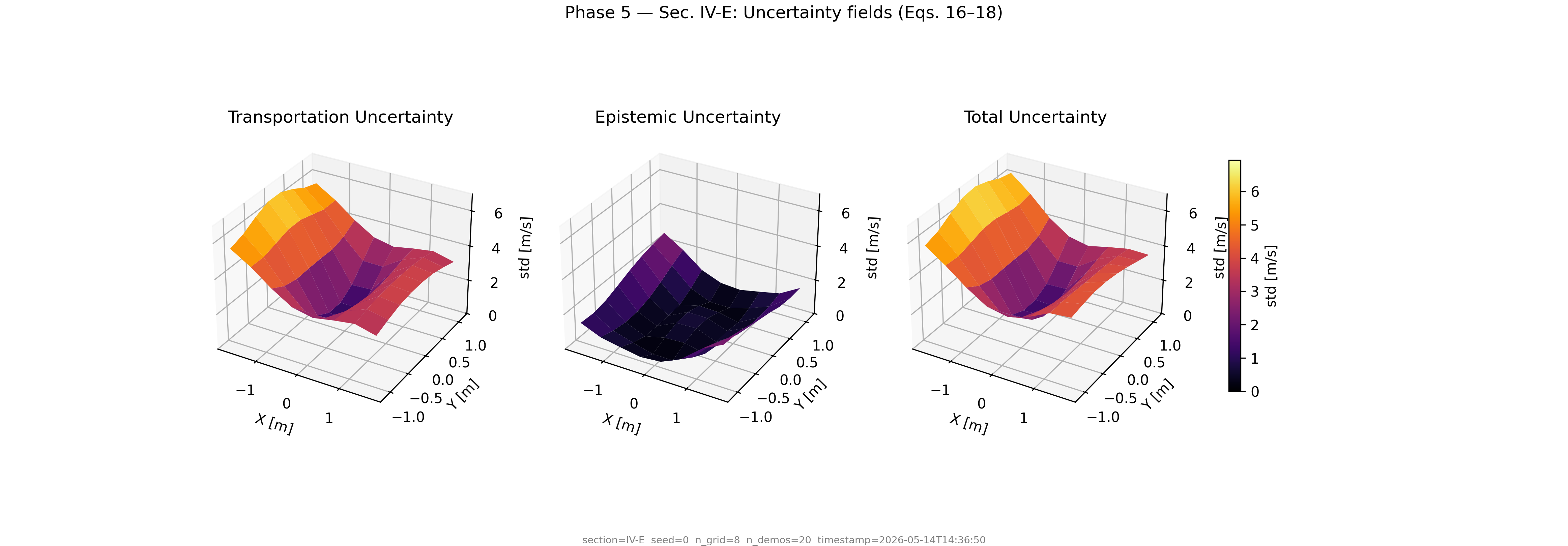 Uncertainty triptych · Fig. 6 · Sec. III-H
Uncertainty triptych · Fig. 6 · Sec. III-H
3D simulation note: Sec. V-B (robot dressing) requires deformable cloth simulation unavailable in our kinematic MuJoCo setup. It is replaced by arm-pose following, which preserves the same generalization challenge: adapting a path to a novel kinematic configuration from a single demonstration. Secs. V-A and V-C (reshelving and surface cleaning) are reproduced as direct analogs.
Baseline comparison — 2D surface cleaning
TP-GPT is the only method with well-calibrated epistemic uncertainty that grows correctly outside the training distribution. Ensemble methods (E-RF, E-NN, E-NF) plateau out-of-distribution; KMP and LE have no uncertainty.
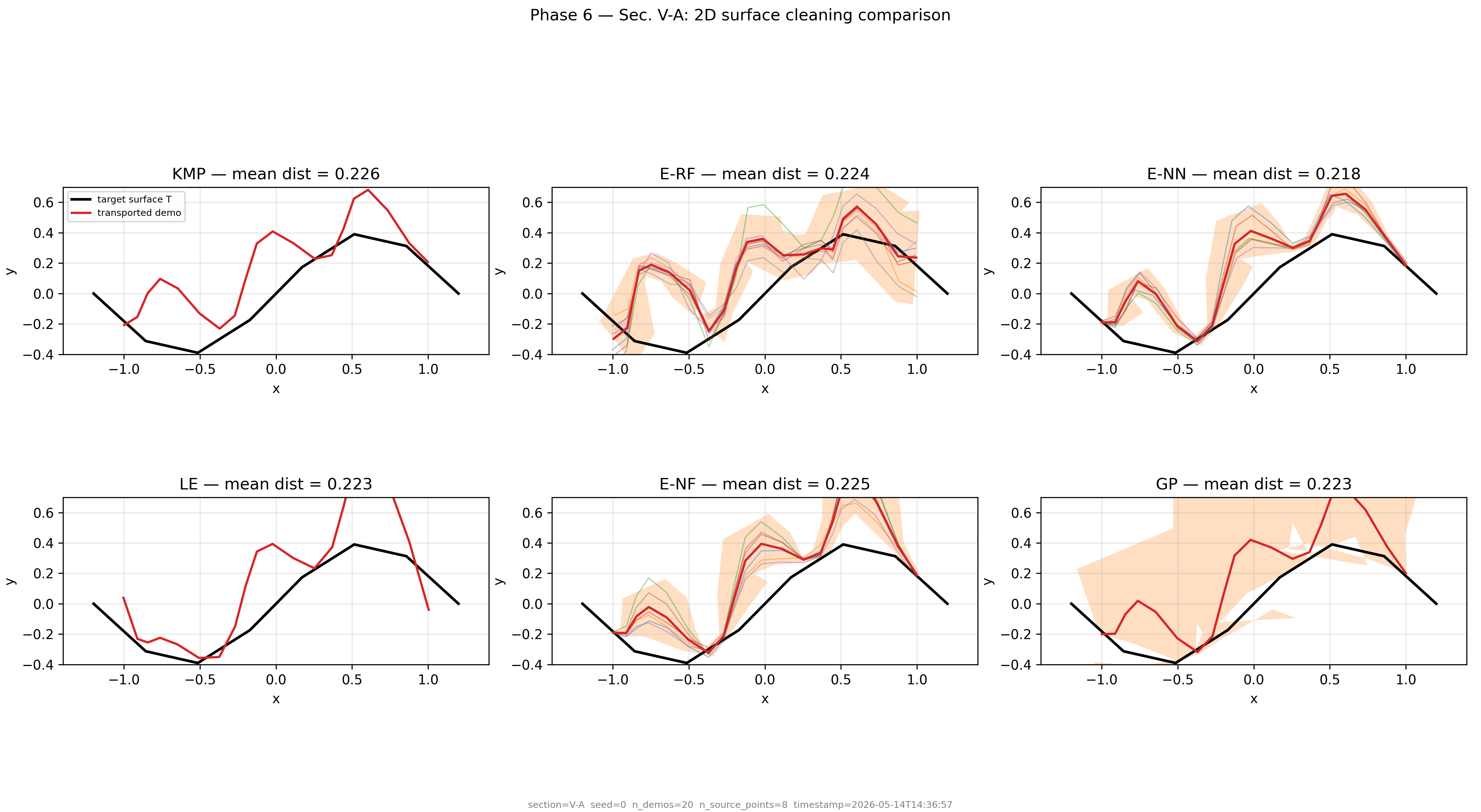 Baseline comparison · Fig. 7 · Sec. IV-A
Baseline comparison · Fig. 7 · Sec. IV-A
Benchmark Performance
TP-GPT reproduced across Secs. IV-A, IV-B. Mann-Whitney U-test ranking: TP-GPT achieves rank 1 on Fréchet distance, area between curves, and DTW. DMP ranks 1 on final position error in this reproduction — a known divergence from the paper caused by the LQR→greedy-GMM simplification in Sec. IV-B (see REPORT.md). Baselines on 20-repetition runs.
Table I · Method comparison
Methods compared on 2D surface cleaning (Sec. IV-A). TP-GPT is the only method with analytical, well-calibrated uncertainty.
| Method | Modality | Velocity gen. | Uncertainty | Type |
|---|---|---|---|---|
| TP-GPT (ours) | GP | ✅ | ✅ | Analytical |
| KMP | Kernel | ❌ | ❌ | None |
| Laplacian Editing | Graph | ❌ | ❌ | None |
| Ensemble RF | Random Forest | ✅ | ✅ | Estimated |
| Ensemble NN | Neural Net | ✅ | ✅ | Estimated |
| Ensemble NF | Norm. Flows | ✅ | ✅ | Estimated |
Training set performance (Fig. 9)
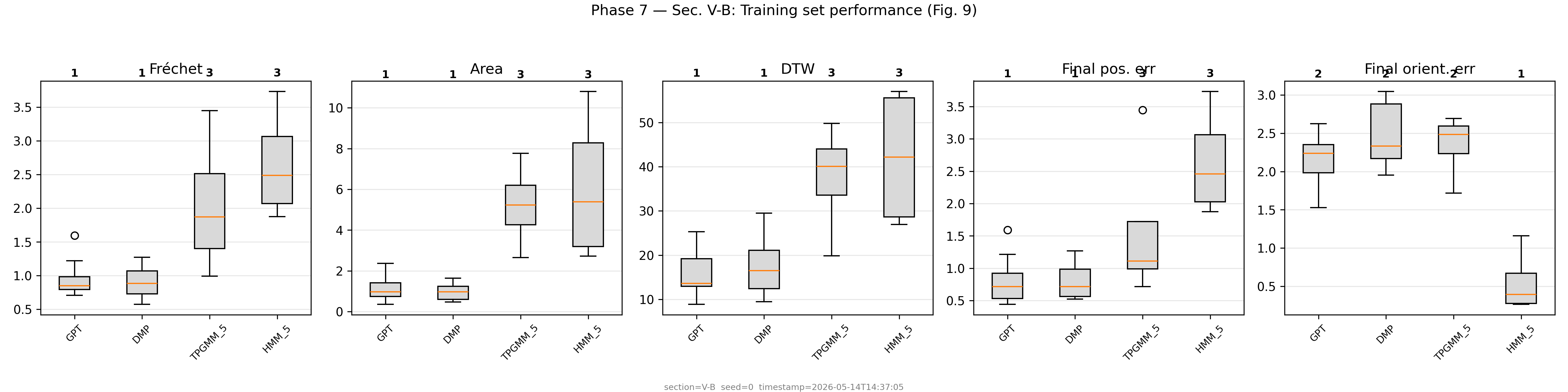 5 metrics · 8 method variants · 20 repetitions
5 metrics · 8 method variants · 20 repetitions
Test set generalization (Fig. 10)
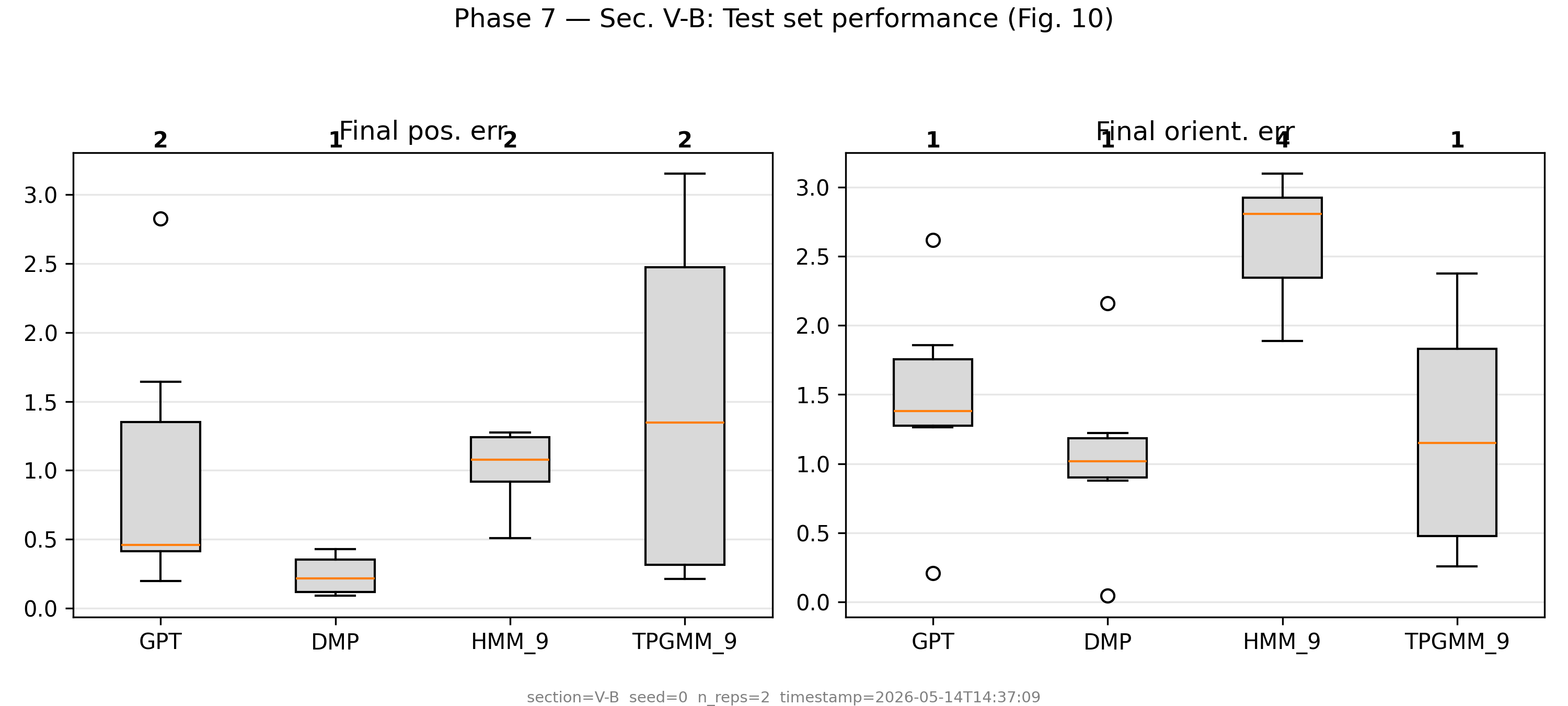 Final position + orientation error · Unseen frame configurations
Final position + orientation error · Unseen frame configurations
Built on open research
Generalization of Task Parameterized Dynamical Systems using Gaussian Process Transportation
Read on arXiv → Original code → Watch paper video →@article{franzese2024tpgpt,
title = {Generalization of Task Parameterized Dynamical Systems
using Gaussian Process Transportation},
author = {Franzese, Giovanni and Prakash, Ravi and Kober, Jens},
journal = {arXiv preprint arXiv:2404.13458},
year = {2024}
}